- DataMigration.AI
- Posts
- Stop Waiting for Perfect Data, Start Getting Real AI Results Now
Stop Waiting for Perfect Data, Start Getting Real AI Results Now
Turning Obstacles into Advantages.
Damian - Data Migration Expert
February 26, 2026
What’s inside?
80% of AI fails due to wrong data strategy, not bad models.
Perfect data is a myth that delays your AI ROI.
You only need 3–5 data sources, not a full migration.
Winners use context, not complete data warehouses.
Manual data work is your biggest hidden bottleneck.
Launch AI in 60 days by skipping over-preparation.
You're about to find out why you don't need perfect data to win your next AI battle.
You probably know this story by heart. Someone tells you that AI will finally work its magic once all of your data is in one place, clean, and under control. You agree. You give the thumbs up to budgets.
You start migrations and governance projects that take years to finish. And then the inevitable happens: deadlines are missed, executives get angry, and the AI project turns into a never-ending pilot.

You don't have to keep going in this circle. This newsletter will give you a clear, step-by-step plan to stop waiting, start delivering, and turn AI into business results in weeks instead of years.
You are not failing at AI; you are doing the wrong thing first
The truth is, AI will fail not because the models are bad, but because the team's approach to data migration is the mission.
They begin with large infrastructure ambitions and bring the business to a standstill until what you’re doing becomes less about a smart initiative and more about a migration program. That’s backwards planning.
Reverse the mindset. Don’t start with the infrastructure. Start with the business outcome you seek, then work out exactly what data you need to achieve it. In most cases, you only need access to a few data sources, not the whole data warehouse.
Without migration as a prerequisite, several wins will come quickly:
Timelines will decrease dramatically
Expenses and risk will decrease
Stakeholders will build confidence through early momentum
Why perfect data is a fantasy and why you should not chase it
Perfect data is tempting. Clean schemas, standardized taxonomies, and clean records are good ideals. However, the cost of seeking perfection is that it holds you back in preparation rather than taking action. Waiting for perfection means that you will never deliver anything.
The cost of perfectionism is as follows:
Months invested in manual profiling and mapping
Endless discussions on schemas and data ownership
A series of governance meetings with no actual product in production

AI does not require perfection to be useful. It requires context, not all copies of everything. Depending on your application, it may require contracts and amendments, or it may require customer conversations and product information. It does not require the entire data lake.
The best course of action is to be pragmatic. Determine the minimum viable context that will provide value, and then deliver on that.
Still waiting for perfect data? Start building with what works today.

How to pick the first use case that gets you traction
You want the quickest route from concept to actual impact. Here is a lean and mean checklist to home in on the best first use case:
High frequency: This is a daily or weekly task, so the benefits add up.
Measurable baseline: You can actually measure the difference, such as average call handle time or number of disputes resolved.
Localized data footprint: The data you need is in three to five systems, tops.
Low cross-domain dependency: This use case doesn’t require six months of enterprise alignment.
Clear owner: A business owner who will drive this result.

Pick one use case that meets all of these, and you’ll quickly demonstrate ROI. Quick wins will establish trust, and trust will open the wallet to move on to phase two.
Ship AI Today: 3 Architectural Hacks You Can Drop In
You don’t have to dismantle and rebuild everything from scratch. Rather, three doable architectural maneuvers enable AI to operate on the data you already own.
1. Context models specific to each use case
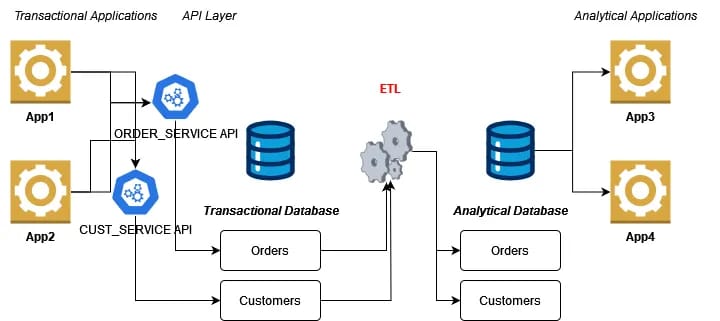
Forget about finding a one-size-fits-all schema. Design tiny, specialized context models, each one representing no more or no less than the entities and relationships specific to your use case. Easy to validate.
2) Federated access and on-the-fly assembly

Leave data where it is. Leverage federated queries, virtual views, and runtime assembly to construct context just in time for queries. No need for ETL cycles or stale context snapshots. You’ll have more current context with less up-front work.
3. Automation for profiling, mapping, and validation

Automate the discovery process. Use intelligent agents and automation to profile sources, propose mappings, and validate outcomes. This reduces manual labor and accelerates trust in the results.
Combine these three maneuvers, and you’ll have AI solutions that are fast, auditable, and low-risk
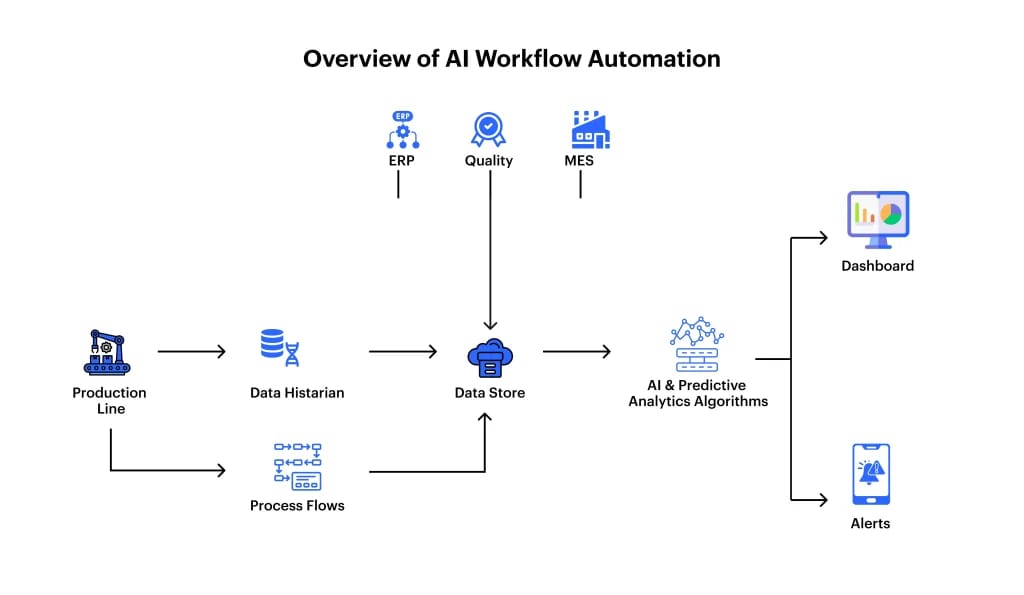
How AI-driven automation changes the data workload
One of the largest changes you can make is to let the AI handle the data plumbing. Today’s AI has a lot to say about structure, finds duplicates, and matches similar fields in other systems. They’re not foolproof, but they’re quick and get your team off the treadmill of busywork.
Here’s what automation brings:
Speed: Profiling that took weeks is now done in a fraction of the time.
Consistency: repeatable mapping rules reduce rework.
Traceability: automated tests produce audit trails that can be shared with regulators and stakeholders.
It’s not magic. It’s engineering. Combine automation with a sharp, specific focus on real-world use cases, and you’ll get the speed you need to deliver real results.
Stop Planning. Start Shipping AI
If you start with one use case and follow these three architectural steps, here is what you can realistically expect in terms of a timeline:
Week 1 to 2 -
Refine the use case with the business owner
Identify minimal data sources and access points
Week 3 to 4 -
Automate profiling and mapping for the selected sources
Build a runtime context assembly pipeline
Week 5 to 8 -
Deploy the AI model in production with a retrieval-augmented context
Validate with business owners
By week 8, you could have a production pilot with real, tangible results. It’s weeks, not months or years.
The questions everyone asks (but rarely says out loud)
You are probably thinking about edge cases. Here are the ones that come up most and how to handle them.
What about data quality?
You will always have data issues. The trick is to validate what matters for the use case. Automate targeted cleaning where it moves the needle. Do not attempt enterprise-wide cleansing as the first step.
What about governance and compliance?
You should build governance, but in a lean way. Embed policies into the runtime assembly and logging. Use role-based access and data minimization to reduce exposure.
For heavy analytics, precompute aggregates and use warehouses as needed. The hybrid approach lets you balance runtime freshness with performance requirements.
This Support Fix in 45 Days (No Big Migration)
Imagine you run a support center. Tickets pile up, customers are frustrated, and resolution times are unpredictable.
Select the billing problems to solve, and let automation take care of them completely. You identify the three key data sources, describe them, and define the fields. You create context dynamically and add a retrieval layer to your AI assistant.
In 45 days, the following happens:
35% of billing tickets were solved without human involvement
Time to resolve has been reduced from 24 hours to 12 minutes
Customer satisfaction increases
This is not a dream. This is what companies actually see when they stop waiting for perfect data.
The Truth: AI Doesn’t Kill Migration
Let’s be clear: migration still has its use in many workloads. Historical analytics, offline training, and large-scale reporting will continue to rely on consolidated data. The trick is to think of migration as a strategic choice, not an automatic requirement.

Use migration when it’s really necessary, but don’t let it be the bottleneck in every AI project. Integrate federation, selective migration, and automation in a way that suits the workload.
Stop Waiting: Deploy Your First AI Flow Today
If you’re looking to bypass the non-actionable areas and get right to impact, consider the feasibility of implementing this strategy with a platform designed specifically for targeted data readiness.
Our platform provides automated profiling, mapping, and validation with the ability to assemble and access at runtime. It provides you with the power you require and the speed you desire, making migration a choice, not a challenge.
Get your first measurable AI outcome, or we will help you iterate until you do.

Want to try migration in a smarter way
If you still need to move some workloads, do it in a smart way. Use a targeted, use-case-driven migration that only moves what needs to be moved. Use automation to do mapping and profiling, and make sure that governance is built in from the start.
Cut the Delay, Start Delivering AI
Pick one specific use case and assign it to one business owner.
Identify the minimal data sources you need and perform automated profiling.
Perform a quick pilot with runtime assembly and measure the effects for 30 days.
Do these three things, and you will be shocked at how quickly the conversation changes in the executive suite.
Final note, because someone has to say it clearly
Perfection makes us slow. If you’re after perfect migration and clean data, you’ll forget what AI is all about. AI is not a blank check for doing lots of technical work-it’s a supercharger for decisions.
Put value first instead of infrastructure first. Concentrate on the minimum viable context, automate the hard work, and move in weeks. Your competitors are already doing this.
The change is simple: focus on outcomes, not architecture, and momentum will follow.
Thank you for reading
DataMigration.AI & Team